
When you just plan your future website you start with structuring data and it’s obvious. But if you try to improve the existing project it’s a common mistake to go through checklists and 10 rules and so on instead of starting from the very beginning.

First of all, you should define your goals.
The next necessary step would be composing the website structure. If you are optimizing an already existing website you should pay extra attention to this point. If you skip it now all your next efforts would be haphazard and not as effective as possible.
You can proceed to build your semantic kernel, linking, improving content, and so on only based on your website structure.
A decent website structure for SEO should be:
- Clean and clear
- no orphan pages that lead nowhere
- no content duplicates (easy auto excerpt) author archives, date archives
Website structure tools (free and paid):
- Website structure diagram creator to plan future website structure:
- Website structure analysis tool for visualization existing website structure
- To generate the sitemap itself: I use the free WordPress plugin Google XML Sitemaps which updates the sitemap as soon as a new post is published
Once you’ve done planning the structure, you might want to visualize your website pages through a prototype.
Clear website structure example
I’ve got a task to divide the website into two new, separate its content and increase SEO organic traffic to both of them. Of course, we’ve started with setting goals and tasks for each of two new projects. Basing on goals and existing content we’ve planned website structure for each website too. Here is an example of one of them:
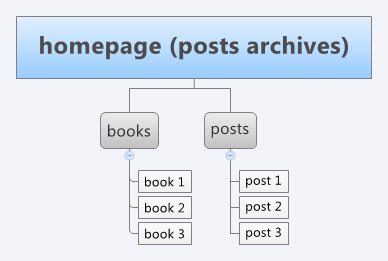
As you can see, here it is rather simple. But this simplicity adds difficulty. We need to connect them all and built nice navigation between posts (about a thousand) and books (a few thousands) to ensure easy access to every single one for visitors and crawlers.
Some tips:
We used tags for posts and custom taxonomies for books.
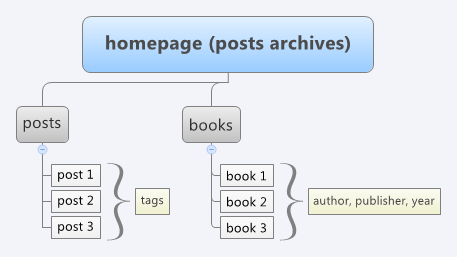
But that’s not enough. How to build really nice internal linking read in detail here.
Website structure best practices for SEO using follow, noindex
When you’ve got your website structure ready you can clearly see parts of your website and tell search crawlers how to treat them. In our example books and posts would be allowed to index and to follow, that’s clear. But what should we do with tags and custom taxonomies: author, publisher, year.
On the one hand there is no real information on these pages — just links to books, and google might consider it irrelevant and exclude it from the search. And if your website got many irrelevant pages it can’t affect good pages ranking too which we of course don’t want. What can we do here?
Option 1 (the wrong way!): You can find advice to disallow tags, taxonomies, and author pages (all pages that got no real content but exist for navigation purposes) in robots.txt so search engines crawlers won’t index them and will index just “good” pages with real content (posts themselves, for example, but not tags or categories).
Option 2 (way to more traffic here!): if you block your taxonomies pages from crawling keep in mind that the search bot won’t crawl these pages at all and won’t read its content and won’t index links to your posts (books etc) there and won’t get to posts through these links. Your taxonomies pages are totally useless for SEO this way. So if you got tags, categories or custom taxonomies you would rather not show it to the search crawler but it contains a lot of links to your main content which you want to get indexed well don’t use robots.txt. Instead, use on-page meta-tags noindex, follow. This way search engine will follow all links on your tag’s archive page but won’t include the page itself in SERP. There are plenty SEO plugins for Worpdress which will do this work for you, personally, I prefer Yoast SEO.
Once your website structure is ready, move to internal linking planning. Good luck!
Leave a Reply